Using different learning schedules
lightfm implements two learning schedules: adagrad and adadelta.
Neither is clearly superior, and, like other hyperparameter choices, the
best learning schedule will differ based on the problem at hand.
This example tries both at the Movielens 100k dataset.
Preliminaries
Let’s first get the data and define the evaluations functions.
import numpy as np
import data
%matplotlib inline
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
from lightfm import LightFM
from lightfm.datasets import fetch_movielens
from lightfm.evaluation import auc_score
movielens = fetch_movielens()
train, test = movielens['train'], movielens['test']
Experiment
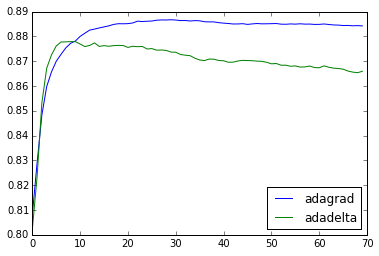
To evaluate the performance of both learning schedules, let’s create two models and run each for a number of epochs, measuring the ROC AUC on the test set at the end of each epoch.
alpha = 1e-3
epochs = 70
adagrad_model = LightFM(no_components=30,
loss='warp',
learning_schedule='adagrad',
user_alpha=alpha,
item_alpha=alpha)
adadelta_model = LightFM(no_components=30,
loss='warp',
learning_schedule='adadelta',
user_alpha=alpha,
item_alpha=alpha)
adagrad_auc = []
for epoch in range(epochs):
adagrad_model.fit_partial(train, epochs=1)
adagrad_auc.append(auc_score(adagrad_model, test).mean())
adadelta_auc = []
for epoch in range(epochs):
adadelta_model.fit_partial(train, epochs=1)
adadelta_auc.append(auc_score(adadelta_model, test).mean())
It looks like the adadelta gets to a better result at the beginning of training. However, as we keep running more epochs adagrad wins out, converging to a better final solution.
x = np.arange(len(adagrad_auc))
plt.plot(x, np.array(adagrad_auc))
plt.plot(x, np.array(adadelta_auc))
plt.legend(['adagrad', 'adadelta'], loc='lower right')
plt.show()
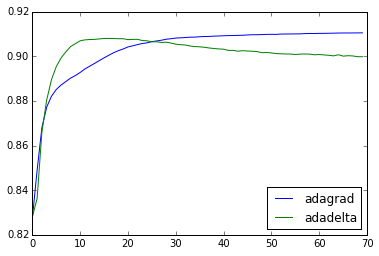
We can try the same for the k-OS loss.
alpha = 1e-3
epochs = 70
adagrad_model = LightFM(no_components=30,
loss='warp-kos',
learning_schedule='adagrad',
user_alpha=alpha, item_alpha=alpha)
adadelta_model = LightFM(no_components=30,
loss='warp-kos',
learning_schedule='adadelta',
user_alpha=alpha, item_alpha=alpha)
adagrad_auc = []
for epoch in range(epochs):
adagrad_model.fit_partial(train, epochs=1)
adagrad_auc.append(auc_score(adagrad_model, test).mean())
adadelta_auc = []
for epoch in range(epochs):
adadelta_model.fit_partial(train, epochs=1)
adadelta_auc.append(auc_score(adadelta_model, test).mean())
x = np.arange(len(adagrad_auc))
plt.plot(x, np.array(adagrad_auc))
plt.plot(x, np.array(adadelta_auc))
plt.legend(['adagrad', 'adadelta'], loc='lower right')
plt.show()