Altering a Postgres Column with Minimal Downtime
Working in the marketing tech team at Lyst, a great part of our day-to-day job is to deal with various online advertising platforms. Naturally, we maintain a copy of all the ads we run in our database, which is on an Amazon RDS-Postgres architecture. We use Python Django database models to manage our data.
Our Postgres was on version 9.4 at that time (migrated to 11 since), however the content in this post should be applicable to later versions too, same if your database is self-hosted.
What’s the problem?
The Django model automatically adds an id column to your tables, which is an auto-increment integer field. You can override this behaviour by specifying a primary key explicitly, however it is not possible if you have a composite primary key, or the table simply doesn’t have one.
This is an integer field by default, whose value can be up to around 2.1 billion in Postgres. Two billion may sound a lot, but unsurprisingly for commercial use cases it is not always enough. One of our tables, called sem_id (used to store uniquely identifiable data of our ads) is approaching this limit and we must do something before it is met, at which point it’s no longer possible to add new rows to the table.
Of course, a precaution would be to make this field bigint in the first place, which is an 8-byte integer and well, probably suitable for your use case unless you are counting the stars in our universe. But it is too late now.
What can we do?
The most straightforward answer is to run an ALTER command:
ALTER TABLE sem_id ALTER COLUMN id BIGINT;
Only if life was so simple! Because of the MVCC model Postgres operates on, altering a column will usually cause a rewrite of the entire table, with few exceptions. Meanwhile it acquires an exclusive lock of the table which means no-one else could access it.
We did this to another table previously when it encountered the same issue. That table was one-fifth of sem_id’s size and the altering command took almost ten hours to complete. In other words, we are looking at a two-day downtime of the sem_id table. However, there are live processes that depend on this table, which can be paused temporarily, but definitely not for two days.
Replicating the column with trigger
Fortunately, triggers come to our salvation. Trigger is a Postgres functionality (and many other relational databases too) which executes queries automatically upon certain events. It allows us to replicate the id column into another of a different data type.
The procedure will be something like this:
1) Create a new id_bigint column, of type bigint:
ALTER TABLE sem_id ADD COLUMN id_bigint BIGINT NULL;
2) Add a trigger to the table, so that id_bigint is updated whenever a new row is inserted.
CREATE OR REPLACE FUNCTION update_bigint_id() RETURNS TRIGGER AS $BODY$
BEGIN
NEW.id_bigint=NEW.id;
RETURN NEW;
END
$BODY$ LANGUAGE PLPGSQL;
CREATE TRIGGER bigint_id_update
BEFORE INSERT ON sem_id
FOR EACH ROW EXECUTE PROCEDURE update_bigint_id();
3) Backfill id_bigint for existing rows
UPDATE sem_id SET id_bigint = id WHERE id_bigint IS NULL;
Step 3) is bound to your system’s I/O capability and is the most time-consuming part of the entire migration process. You should optimise it by breaking it down into small sub queries (e.g. only update a small id range at a time), so that it doesn’t lock your entire table at once and can execute more efficiently. In our case it takes around four days to finish, as we have a couple of weeks before the deadline we can live with it.
Once these steps are accomplished, the id_bigint column will have exactly the same values as id. Migration can be completed by the following queries in transaction:
BEGIN;
LOCK TABLE sem_id IN SHARE ROW EXCLUSIVE MODE;
DROP TRIGGER bigint_id_update ON sem_id;
ALTER SEQUENCE sem_id_seq OWNED BY sem_id.id_bigint;
ALTER TABLE sem_id ALTER COLUMN id_bigint SET DEFAULT nextval(sem_id_seq);
ALTER TABLE minion_semid DROP COLUMN id;
ALTER TABLE minion_semid RENAME COLUMN id_bigint TO id;
COMMIT;
Two things to keep in mind:
- We need to move the sequence over, so that id_bigint can auto increment
- Table sem_id must be locked at the beginning of the transaction, to prevent new rows being inserted for the duration
This transaction should take no more than a few seconds, a great improvement over the 50-hour downtime!
Making it a primary key
You may have noticed something missing in the process above - the new id column is not a primary key. As this column is nullable, making it a primary key involves a NOT NULL constraint check and adding a unique index. This again will lock the table and incurs further downtime.
We can shorten the downtime by creating the unique index beforehand and tell Postgres to use this index when creating the primary key constraint:
CREATE UNIQUE INDEX CONCURRENTLY sem_id_uniq ON sem_id(id);
ALTER TABLE sem_id ADD PRIMARY KEY USING INDEX sem_id_uniq;
Note the CONCURRENTLY keyword - this allows the index to be built without acquiring an exclusive lock of the table. Of course, adding the primary key will still lock the table as it needs to enforce the NOT NULL constraint, but should be a lot faster since it can skip the index-creation phase.
An alternative is to create an invalid NOT NULL CHECK constraint first and then validate it:
ALTER TABLE sem_id ADD CONSTRAINT sem_id_not_null CHECK (id IS NOT NULL) NOT VALID;
ALTER TABLE sem_id VALIDATE CONSTRAINT sem_id_not_null;
The validation acquires a SHARE UPDATE EXCLUSIVE lock, so other connections can still perform reads and writes. As a result, the table won’t have a primary key, but the unique index and NOT NULL constraint are functionally equivalent, and we won’t face any downtime here.
Handling dependency
So far so good, this plan works perfectly if sem_id is a standalone table. However, as we mentioned above it is at the core of our daily operations, therefore a few other tables are dependent on it.
For the purpose of this article, we’ll just demonstrate one table here, namely keyword, which has a foreign key constraint referencing sem_id’s id column. We need to migrate the referencing column sem_id_id together with the constraint.
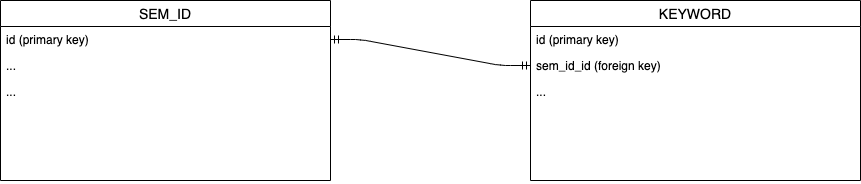
Similar to the sem_id table, we initiate a replication process of the sem_id_id column.
1) first by adding a trigger:
CREATE OR REPLACE FUNCTION update_keyword_bigint_semid() RETURNS TRIGGER AS $BODY$
BEGIN
NEW.sem_id_bigint=NEW.sem_id_id;
RETURN NEW;
END
$BODY$ LANGUAGE PLPGSQL;
CREATE TRIGGER keyword_bigint_semid_update
BEFORE INSERT ON keyword
FOR EACH ROW EXECUTE PROCEDURE update_keyword_bigint_semid();
2) Then backfill existing rows:
UPDATE keyword SET sem_id_bigint = sem_id WHERE sem_id_bigint IS NULL;
Again, use subqueries and perhaps parallelisation.
3) Add index concurrently:
CREATE INDEX CONCURRENTLY keyword_sem_id_id_cp ON keyword(sem_id_bigint);
We need a forieign key constraint on this column, referencing the sem_id table. Adding it naively will lock the table, therefore we fall back to the “create invalid constraint and validate” approach.
ALTER TABLE keyword ADD CONSTRAINT keyword_sem_id_id_fk_sem_id_id_cp FOREIGN KEY (sem_id_bigint) REFERENCES sem_id(id_bigint) NOT VALID;
ALTER TABLE keyword VALIDATE CONSTRAINT keyword_sem_id_id_fk_sem_id_id_cp;
Last but not least, add this foreign key migration snippet before the finalisation of sem_id migration.
BEGIN;
LOCK TABLE keyword IN SHARE ROW EXCLUSIVE MODE;
ALTER TABLE keyword DROP CONSTRAINT keyword_sem_id_id_fk_sem_id_id;
ALTER TABLE keyword RENAME CONSTRAINT keyword_sem_id_id_fk_sem_id_id_cp TO keyword_sem_id_id_fk_sem_id_id;
DROP TRIGGER keyword_bigint_semid_update ON keyword;
ALTER TABLE keyword DROP COLUMN sem_id_id;
ALTER INDEX keyword_sem_id_id_cp RENAME TO keyword_sem_id_id;
ALTER TABLE keyword RENAME COLUMN sem_id_bigint TO sem_id_id;
COMMIT;
Conclusions
All done. With triggers and NOT VALID constraints, we managed to reduce the migration downtime from two days to just two hours. And remember that 99% of the time here is to add the primary key - if you are migrating a non-primary-key column, or if it can be left out, or you don’t mind using a NOT NULL CHECK constraint instead, the downtime can be reduced dramatically to just minutes or even seconds.